В этой теоретической заметке подробно рассмотрим вывод команды top - утилиты для базовой диагностики Linux.
🖐️Эй!
Подписывайтесь на наш телеграм @r4ven_me📱, чтобы не пропустить новые публикации на сайте😉. А если есть вопросы или желание пообщаться по тематике — заглядывайте в Вороний чат @r4ven_me_chat🧐.
top - это утилита-менеджер процессов для командной строки Linux, которая предоставляет динамическое, в реальном времени, представление запущенных процессов и системных ресурсов (CPU, память).
Каждому продвинутому пользователю Linux настоятельно рекомендуется знать про top, уметь с ним работать и интерпретировать его вывод.
Про показатели, отображаемые в выводе top очень часто спрашивают на IT собеседованиях☝️.
Для вызова менеджера процессов просто выполните:
top -c📝 -c (command) - показывает полную команду процесса, включая аргументы.
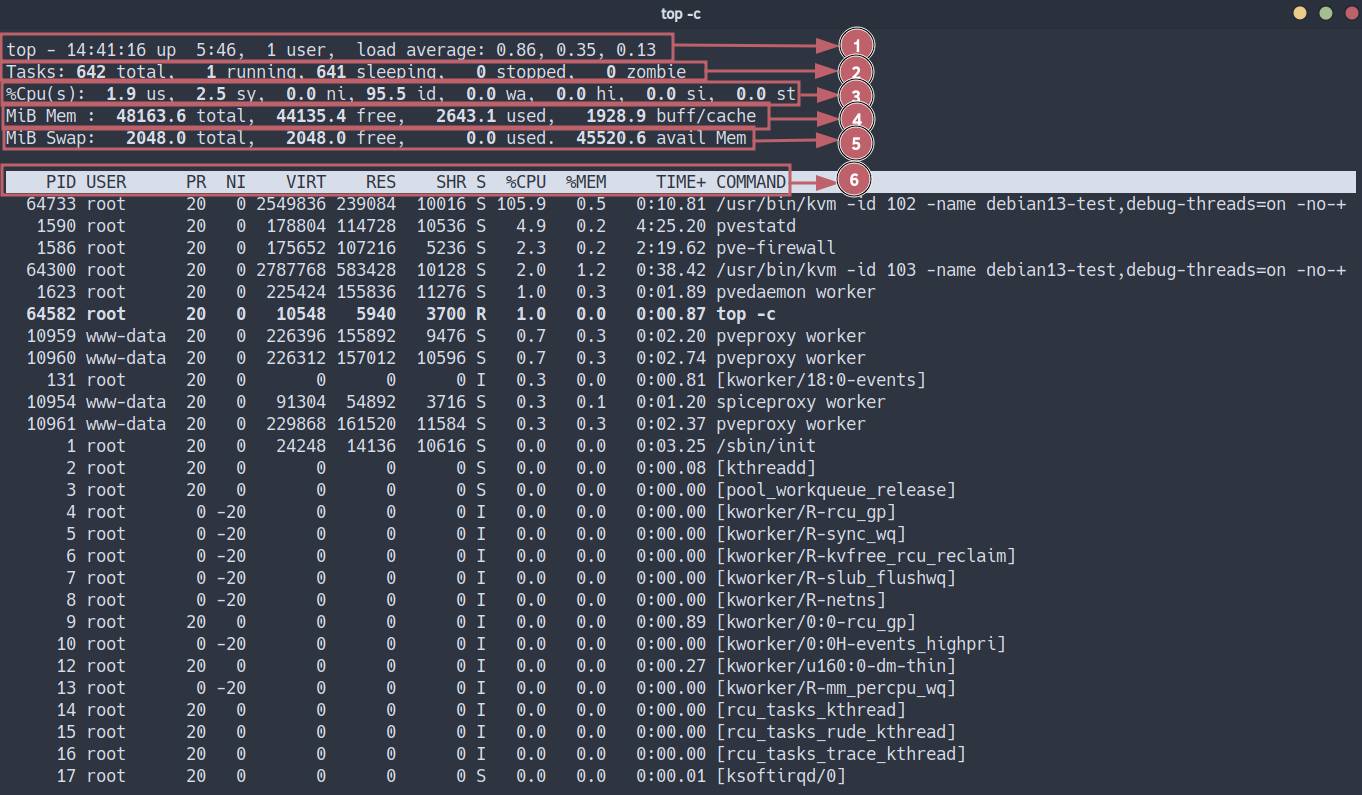
Ниже подробный разбор вывода данной утилиты.
Строка 1 - Время запуска, пользователи и Load Average
top - 14:41:16 up 5:46, 1 user, load average: 0.86, 0.35, 0.13Разбор показателей:
14:41:16- текущее системное время;up 5:46- время непрерывной работы ядра (uptime) с момента последней загрузки;1 user- количество активных терминальных сессий (tty/pts);load average(LA) - экспоненциально взвешенное скользящее среднее длины очереди выполнения процессов на CPU за 1, 5 и 15 минут🤯.
Как интерпретировать?
LA в Linux - это сумма процессов в двух состояниях:
- Running/Runnable (
R) - процессы, выполняющиеся на CPU или стоящие в очереди на выполнение (Ready queue). - Uninterruptible Sleep (
D) - процессы, ожидающие ввода-вывода (I/O disk, NFS) или блокировки ядра.
Кейсы:
LA < кол-ва ядер- система работает в штатном режиме, простоев в очереди нет;LA > кол-ва ядер- возникает конкуренция за ресурсы, появляются задержки (Latency);High LA + Low CPU Usage- признак узкого места в дисковой подсистеме (I/O Wait). Процессы блокируются в ожидании данных.
Команды диагностики
w # Показать, кто залогинен и их текущие процессы
uptime # Быстрый вывод LA и аптайма
lscpu # Проверить количество ядер (CPU(s)), чтобы корректно оценить LA
sar -q 1 5 # (sysstat) История длины очереди выполнения (runq-sz)Строка 2 - Сводка задач (Tasks)
Tasks: 642 total, 1 running, 641 sleeping, 0 stopped, 0 zombieРазбор показателей:
total- общее количество процессов, запущенных в системе;running- процессы, владеющие контекстом CPU прямо сейчас или готовые к этому;sleeping- процессы в ожидании наступления определенного события или доступности ресурса;stopped- процессы, получившие сигнал остановки (SIGSTOP,SIGTSTP);zombie- дочерние процессы, завершившие выполнение, код возврата которых еще не считан родительским процессом.
Как интерпретировать?
- Большое количество
sleeping- норма для многозадачной ОС (демоны, ожидание ввода); - Наличие
stoppedчасто свидетельствует о ручной отладке или приостановке задач (Ctrl+z); zombieне потребляют память или CPU, но занимают дескриптор в таблице процессов (PID).
Команды диагностики
# Вывести все процессы
ps -ef
# Дерево процессов (помогает найти родителя зомби)
pstree -p -t -n -C age
# Найти зомби и PID их родителей
ps -eo user,pid,ppid,state,comm | awk 'NR==1 || $4=="Z"'Строка 3 - Статистика CPU
%Cpu(s): 1.9 us, 2.5 sy, 0.0 ni, 95.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stРазбор показателей (процент времени):
us(User) - код пользовательского пространства (приложения, БД, веб-серверы) со стандартным приоритетом;sy(System) - код пространства ядра (системные вызовы, драйверы, управление памятью);ni(Nice) - код пользовательского пространства с измененным приоритетом (renice);id(Idle) - время простоя процессора;wa(I/O Wait) - время простоя CPU, пока система ожидает завершения операций ввода-вывода (диск/сеть);hi(Hardware Interrupts) - обработка аппаратных прерываний (сетевые карты, контроллеры дисков), время CPU, потраченное на обработку сигналов от “железа”;si(Software Interrupts) - обработка программных прерываний (softirqs, планировщик, RCU), время CPU, потраченное на отложенную обработку задач ядра;st(Steal Time) - время, “украденное” гипервизором для других виртуальных машин (актуально только для VM).
Как интерпретировать?
High sy (>20%)- неэффективные системные вызовы, проблемы с драйверами, огромное количество контекстных переключений;High wa- узкое место - диск, процессор простаивает, ожидая данных;High si- часто указывает на сетевой шторм (пакетная нагрузка) или перегрузку стека TCP/IP;High st- “шумные соседи” на физическом хосте, возможно совместное использование ресурсов с другими ВМ.
Команды диагностики
mpstat -P ALL 1 # (sysstat) Нагрузка по каждому ядру отдельно
cat /proc/interrupts # Посмотреть счетчики прерываний (для диагностики hi/si)
dmesg | tail # Логи ядра (ошибки драйверов, оборудования)
iostat -xz 1 # Детальная статистика по диску (для диагностики wa)Строка 4 - Память (Physical RAM)
MiB Mem: 48163.6 total, 44135.4 free, 2643.1 used, 1928.9 buff/cacheРазбор показателей:
total- общий объем физической памяти;free- память, не содержащая никаких данных;used- используемая память, вычисляется какtotal - free - buff/cache;buff/cache:buffers- память, которая содержит суперблоки, битовые карты, заголовки групп, inode, dentry и др.;cache- память, которая содержит кэш страниц (page cache): содержимое файлов на диске, закэшированное в RAM;
avail(available) - оценка памяти, доступной для запуска новых приложений без ухода в своп (пространство, которое можно моментально освободить).
Как интерпретировать?
- Linux исповедует принцип: “Свободная память - потраченная память”.
- Высокий buff/cache - это норма. Linux кэширует дисковые операции тем самым ускоряя работу с диском. При нехватке памяти ядро мгновенно очистит страницы кэша.
- Постоянный рост
usedпри сниженииavailможет свидетельствовать об утечке памяти.
Команды диагностики
free -h # Классический вывод памяти
vmstat -s # Детальная статистика событий памяти
slabtop # Анализ кэша объектов ядра (dentry, inodes)Строка 5 - Память (swap)
MiB Swap: 2048.0 total, 2048.0 free, 0.0 usedПространство на диске, используемое для выгрузки неактивных страниц памяти из RAM.
Разбор показателей:
total- всего swap;free- свободно swap;used- использовано swap.
Как интерпретировать?
- used > 0, но стабильно: ядро выгрузило давно неиспользуемые страницы, чтобы освободить RAM, например, под дисковый кэш. Это нормальное поведение.
- Активный рост used + рост wa: трэшинг (thrashing) - система тратит больше времени на перекачку данных между RAM и диском, чем на полезную работу. Сопровождается критическим падением производительности.
Команды диагностики
swapon -s # Показать активные разделы подкачки и приоритеты
vmstat 1 # Столбцы si (swap in) и so (swap out) - если не 0, идет активный свопингСтрока 6 - Таблица процессов
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMANDРазбор столбцов:
PID(Process ID) - уникальный идентификатор процесса;USER- эффективный идентификатор пользователя (EUID), от которого запущен процесс;PR(Priority) - динамический приоритет планировщика ядра (RT - Real Time);NI(Nice) - значение “уступчивости” (-20 - высший приоритет, +19 - низший). Влияет наPR;VIRT(Virtual Image) - виртуальный объем памяти, зарезервированный процессом (код + данные + разделяемые библиотеки + страницы в swap). Не показывает реальное потребление физической RAM;RES(Resident Size) - не выгруженная в swap физическая память, используемая процессом (code + data). Основной показатель потребления RAM;SHR(Shared Mem) - часть памяти RES, которая может быть разделена с другими процессами (библиотеки glibc и др.);TIME+- суммарное время CPU, затраченное процессом с точностью до сотых секунды;COMMAND- команда запуска процесса.
Состояния процессов (Столбец S)
Это наиболее важный столбец для глубокой диагностики.
| Код | Статус (State) | Техническое описание | Интерпретация |
|---|---|---|---|
R | Running | Running or Runnable | Процесс либо исполняется на ядре, либо находится в очереди планировщика (Run queue). |
S | Sleeping | Interruptible Sleep | Ожидает события (завершения ввода, таймера, сигнала). Может быть прерван сигналом. |
D | Disk Sleep | Uninterruptible Sleep | Процесс ожидает ответа от оборудования (обычно I/O). Его невозможно убить (kill -9 не сработает), пока драйвер не вернет управление. Скопление D-процессов повышает Load Average. |
Z | Zombie | Zombie | Процесс завершен (exit()), память освобождена, но запись в таблице процессов осталась, так как родитель не вызвал wait(). |
T | Stopped | Stopped | Остановлен сигналом управления заданиями (SIGSTOP/SIGTSTP) или отладчиком (ptrace). |
t | Tracing | Tracing stop | Остановлен отладчиком во время трассировки. |
I | Idle | Idle (Kernel thread) | Поток ядра в режиме простоя (не учитывается в Load Average). Обычно процессы [kworker]. |
Команды диагностики процессов
pidstat -r -p <PID> 1 # Детальная статистика по памяти конкретного PID (включая утечки)
pidstat -d -p <PID> 1 # Статистика I/O конкретного процесса (кто пишет на диск?)
strace -p <PID> # (Advanced) Перехват системных вызовов, показывает, что процесс делает прямо сейчас
pmap -x <PID> # Карта памяти процесса
iotop -o -P -d 5 # Интерактивный монитор I/O по процессам (найти виновников D-статуса)
kill -9 <PID> # Принудительное завершение (SIGKILL)
renice -n 10 -p <PID> # Снизить приоритет процесса "на лету"Полезные сочетания клавиш в интерактивном top
P- сортировка по CPU;M- сортировка по памяти;T- сортировка по TIME+;c- показывать полный командный путь/аргументы;u- фильтрация по пользователю;k- послать сигнал (kill);r- renice;H- показывать потоки;f- выбрать/отключить колонки;o- задать порядок сортировки;1- показать отдельную загрузку по каждому ядру;z- включить цветовое отображение.
Полезная команда для вывода в скрипт/лог (non-interactive):
top -b -n 1 Она фиксирует состояние всех процессов на момент выполнения.
Также существует популярные менеджеры htop - удобнее интерактивно, и atop, который способен сохранять историю показателей, но уже другая история😉.
Подробнее про управление процессами читайте в отдельной статье: 🔗 Командная строка Linux, процессы: команды jobs, fg, bg, ps, pgrep, kill, pkill, htop
Интересный кейс из чата
Сможете прокомментировать такой top?) Всего 1 запущенный процесс, на 8 ядрах грузит их все, но LA почти 100. При этом сервер весьма отзывчив на команды и не выглядит перегруженным.
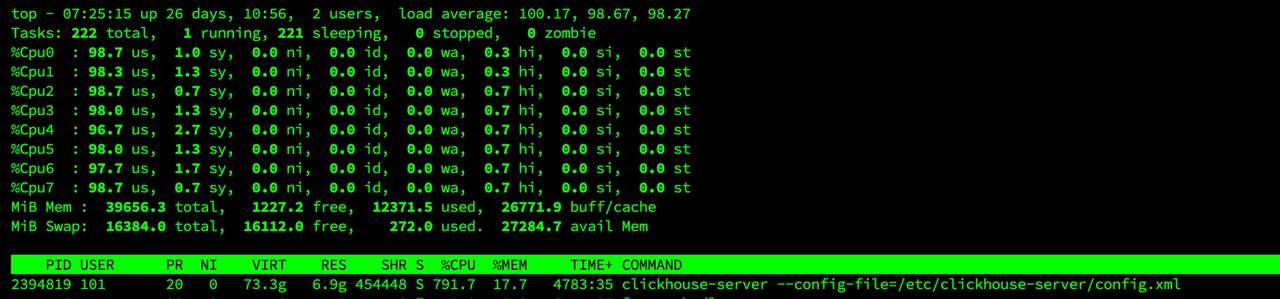
Такую ситуацию часто наблюдаю на VMware в виртуалках с процессами, которые очень любят CPU, но при этом созданной виртуалке не задают лимит по CPU - в VMware это задается через ограничение по частоте в MHz - умножается частота ядра процессора на их кол-во - этот вот суммарный ресурс, который доступен всем виртуалкам и можно задавать для VM лимит в MHz, больше которого она не может потребить, желательно сделать его равным тому кол-ву ядер, что выделили под виртуалку. Иначе она может съесть все доступные свободные ресурсы CPU, забрав их неявно у других виртуалок, что здесь и наблюдается.
Это можно увидеть в мониторинге VMware что виртуалка потребляет больше 100% CPU - в моем конкретном примере это было 125%. При этом, судя по всему, расчет load average ломается, когда он видит, что на процессы уходит больше процессорного времени, чем может быть вообще в наличии ) Я видел load average в 800 и выше на 8 ядрах на тяжелых математических расчетчиках, реально потребление при этом было в 2 раза выше, чем выделено ресурсов. Это был своеобразный лайфхак, потому что по лицензии там можно было использовать только 8 ядер)
